The Mission Is the Unit of AI Work
People are engineering larger jobs out of agent sessions. Missions make those jobs explicit enough to govern, route, resume, and account for.
The current frontier workflow rarely lives in one chat.
It is more likely to involve several agent sessions, a coding harness, a browser, an eval loop, project instructions, local files, MCPs, skills, and the file system slowly accumulating state. Sometimes the harness remembers what happened. Sometimes the user writes intermediary markdown files to capture decisions, partial plans, or what failed. Sometimes the memory is just implicit in the current worktree and the terminal history.
Each session usually owns a different slice of work: one session implements a feature, another investigates a failure, another reviews a diff, another researches a market, another runs or analyzes an eval. Some of this can happen inside a single harness now, but the operating burden is still familiar: the human keeps track of what each run was supposed to do, what context it had, what it tried, where it got stuck, and what should happen next.
As agents become more capable, users naturally give them work that spans more than one prompt, one tool call, or one terminal session. The model improvements that matter most for agent work are increasingly improvements in planning, tool use, recovery, and sustained execution. Anthropic's Fable 5 launch is a useful marker here: the framing was not just better coding, but more capable long-horizon agentic work, tool use, and recovery.
The response has been a wave of informal loop engineering. Users set up goal modes, scripts, worktrees, subagents, MCPs, skills, scheduled checks, eval loops, and external memory so agents can continue without being manually prompted every few minutes. A layer above individual agent harnesses is also starting to form: one that makes sessions more composable, governable, shareable, and portable across models and tools.
That layer is necessary, but composition alone does not define the larger job. A loop may describe how an agent keeps moving. A harness may describe how agents are composed or controlled. The operating contract for the work is still often scattered across prompts, project config, tool permissions, chat history, model-specific memory, files, and the user's head.
A goal like this is easy to type:
Find a GTM channel with real signal.
The loop is also easy to sketch: research channels, pick one, draft copy, build a list, ask before sending, wait for replies, check results, and try again.
The hard part is everything around the loop.
What counts as signal? What is the budget? How many channels can be tested? Which tools can enrich leads? Which model should write copy? Which actions need approval? Where do replies get tracked? How long should the system wait before judging a batch? What happens when the first branch fails? Which learnings should carry forward, and which failed attempts should be compressed or discarded?
Those questions are not just setup. They are the contract of the work. Today, that contract is usually implicit. It lives partly in the prompt, partly in the session, partly in tool configuration, partly in model-specific memory, and partly in the human's head. That is why larger agent work starts to break down even when the individual agents are strong.
Where sessions start to break
The failure modes are becoming familiar.
The contract is underspecified. A goal like "get customers," "improve this agent," or "launch this feature" can start a loop, but it does not define enough about the work: budget, evidence, cadence, permissions, stop conditions, acceptable risk, or what should happen after a failed attempt. The agent may keep moving, while the operating boundary remains implicit.
Sessions sprawl. The work gets distributed across terminals, chats, worktrees, browser sessions, local scripts, cloud jobs, and notes. The user has to remember which session is waiting, which one is blocked, which one finished, and which decision in one session should change the behavior of another.
Context rots. Long sessions preserve continuity by carrying everything forward, including stale assumptions, failed branches, repeated tool output, obsolete instructions, and intermediate artifacts that should not influence the next step. More context is not the same as better context.
Tool access becomes accidental. Skills, MCPs, project files, secrets, and permissions are often inherited from global or project-level configuration. That is convenient for a short run, but a larger job needs an explicit policy for which tools are required, which are allowed, which are risky, and what fallback exists if something is missing.
Model choice becomes an operating constraint. A job tied to one model or one vendor inherits that system's strengths, weaknesses, cost profile, context behavior, memory behavior, tool surface, availability, policy surface, and product lifecycle. Fable 5 is a good example of both sides of this: it validated the direction toward more agentic, long-horizon models, and its temporary suspension showed why larger work should not depend on a single model remaining available in exactly the same way. For larger work, the question should be which worker, model, context, and toolset is right for this step of the job. That decision should belong to the work being attempted, not to whichever session happened to start first.
Memory fragments. A rejected outreach tone, an approved artifact, a useful eval failure cluster, and a pruned branch may all live in different places. The learning belongs to the larger job, not to the session where it happened.
Spend loses accountability. Once agents run for hours, token spend and retries need a unit of accounting. Without a receipt, it is hard to know what consumed budget, what was tried, what failed, what evidence came back, and whether the next step is worth it.
These are not edge cases. They are the normal result of trying to make session-based tools do mission-shaped work.
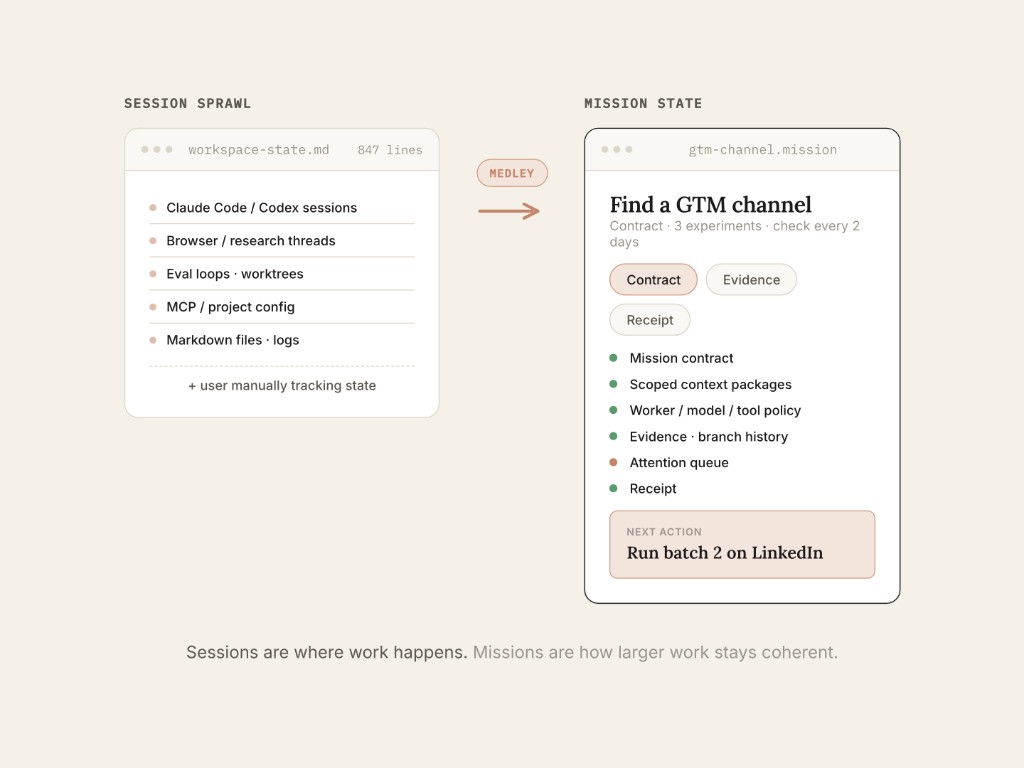
Sessions are where work happens. Missions are how larger work stays coherent.
Context rot is now a systems problem
For a while, the obvious answer to context problems was "give the model more context." Larger context windows helped. They made agents more capable, especially when working inside codebases or long documents.
Long-running work has a different problem. The issue is not only that the context window is too small. The issue is that the unit of context is wrong.
A long session becomes a transcript of everything that happened. That transcript contains useful information, but it also contains noise: abandoned assumptions, half-correct plans, failed attempts, irrelevant tool output, stale user instructions, and artifacts that were useful three steps ago but harmful now.
If the next worker inherits the whole transcript, it has to rediscover which parts matter. If the session is summarized too aggressively, it may lose the reasoning behind important decisions. If the user manually extracts the key points into a notes file, the user becomes the context engineer.
Mission-shaped work needs curated state, not transcript accumulation.
A mission should know:
- the current contract;
- the active assumptions;
- the accepted decisions;
- the open questions;
- the evidence collected;
- the branches that were pruned and why;
- the artifacts worth keeping;
- the context each next worker actually needs.
This matters more as work gets decomposed. A copy worker does not need every eval log. A code worker does not need every lead-enrichment attempt. A reviewer does not need the full chat that produced an artifact; it needs the artifact, acceptance criteria, known risks, and relevant decisions.
Working everything through one session often looks like continuity. In practice, it can become context rot. The better pattern is to preserve the mission state and send each worker a scoped context package.
| Transcript accumulation | Failure mode | Mission-state alternative |
|---|---|---|
| Failed branches | Next worker inherits dead ends and retraces the same mistakes | Pruned branches with reasons preserved at mission level |
| Stale assumptions | Old decisions keep influencing new steps | Active assumptions list that updates when evidence changes |
| Repeated tool output | Context window fills with redundant logs | Scoped context packages per worker |
| Hidden decisions | Reasoning buried in chat history | Accepted decisions recorded in mission state |
| Intermediate artifacts | Useful three steps ago, harmful now | Artifacts tagged and scoped to the workers that need them |
Tool availability is not tool governance
A similar problem is emerging around tools, skills, MCPs, and project configuration.
A session may inherit a global set of tools. A project may define a set of MCPs. A user may have local scripts, repo access, browser state, API keys, subscription-based tools, and private files available in the environment.
That is useful. It is not the same as deciding what a larger job should be allowed to use.
For a GTM mission, the system may need browser research, a spreadsheet, a CRM export, a writing skill, an enrichment source, and approval before sending anything. For a launch mission, it may need repo access, test commands, docs context, changelog conventions, a support-notes template, and approval before publishing or emailing users. For an agent-improvement mission, it may need eval access, prompt/config files, model-routing rules, latency and cost guardrails, and a reviewer before accepting a new configuration.
Those should not be accidental properties of whatever session happened to start the work.
A larger job needs a tool policy:
- which tools are required;
- which tools are optional;
- which tools are allowed;
- which tools are risky;
- which tools are unavailable;
- what fallback exists;
- which worker receives which tool;
- what evidence each tool is expected to produce;
- which actions require human approval.
The same applies to skills and MCPs. They should not only be inherited from a project or global config. They should be assigned because the mission needs them.
Tool access should be part of the mission contract.
The missing object is the contract
A mission is not just a larger task. It is the contract and state layer for a larger job.
For a mission like "find a GTM channel with real signal," the contract might look like this:
Target:
Identify one channel with enough qualified replies to justify a second batch.
Budget:
Two weeks, $500, three channel experiments.
Allowed actions:
Research, draft, enrich leads, prepare batches, analyze replies.
Restricted actions:
Do not send outreach, publish pages, spend money, or contact people without approval.
Evidence:
Reply rate, positive reply quality, booked calls, manual notes.
Cadence:
Check results every two days after each batch.
Tools:
Browser, spreadsheet, CRM export, enrichment source, writing model.
Worker/model policy:
Use stronger models for positioning and synthesis.
Use cheaper or local models for extraction and deduping.
Use a reviewer before any external-facing artifact.
Stop conditions:
Stop a channel if reply quality is poor after the first batch.
Stop the mission if budget is exhausted or no channel shows signal.
Receipt:
Record channels tried, messages drafted, leads enriched, models/tools used,
cost, evidence, pruned branches, learnings, and recommended next step.
That is more than a prompt. It is the operating boundary for the work.
The same pattern applies outside GTM.
A website experiment is not just "rewrite the homepage." It needs a hypothesis, variant, approval rule, publishing path, analytics source, evidence window, learning, and next test.
An agent-improvement mission is not just "make this agent better." It needs a baseline, failure analysis, candidate changes, eval runs, cost and latency guardrails, comparison criteria, accepted configuration, and stopping condition.
A feature launch is not just "ship the code." It needs implementation, review, tests, docs, changelog, launch email, support notes, and approval before external-facing changes.
The mission contract does not guarantee the outcome. It makes the attempt explicit enough to execute, inspect, route, price, pause, resume, and improve.
This practice is still not well defined. People are experimenting with goal modes, loop scripts, subagents, worktrees, MCPs, skills, project instructions, local memory files, eval harnesses, scheduled runs, and human review gates. The category is being invented in practice before it has clean language.
A mission contract is a way to formalize what people are already trying to do manually.
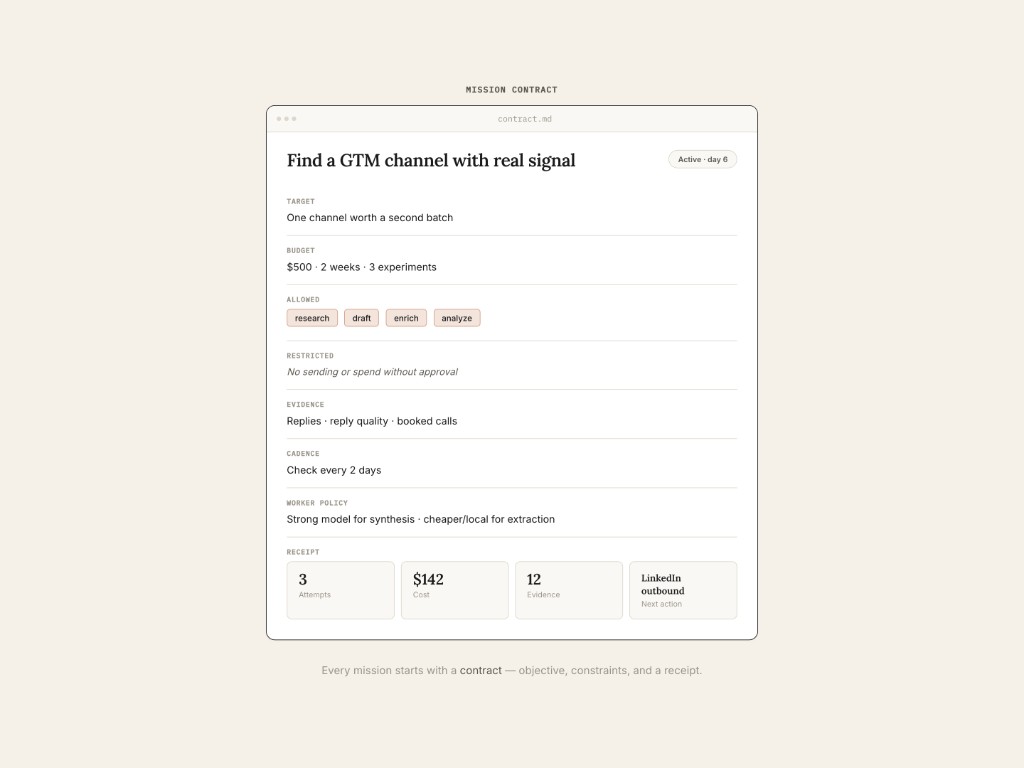
Every mission starts with a contract — objective, constraints, and a receipt.
Decomposition is not just project management
It is tempting to treat decomposition as project-management chrome: break the job into tasks, put the tasks on a board, let agents work through them.
That understates what changes when work is decomposed well.
Decomposition changes the model's job. It changes the context each worker sees. It changes which tools are available. It changes the verification path. It changes the cost profile. It changes the failure modes.
We saw this in our prior work with Spine Swarm. The system reported #1 results on GAIA Level 3 and DeepSearchQA, and the architecture behind those results was not one model in one long prompt. It combined a block-based workspace, multi-agent orchestration, structured handoffs, context compaction, and task-optimized model selection. Source: Spine Swarm benchmark post
The relevant lesson was not that a canvas is always the right interface. The deeper lesson was that structure changes outcomes.

The benchmark lesson: structure changes outcomes.
In that benchmark architecture, an orchestrating agent decomposed complex tasks into subtasks, assigned specialized persona agents, mapped dependencies, delegated work, and synthesized results. Reviewer agents checked outputs before they passed downstream, and structured handoffs were designed to be consumed efficiently by the next agent instead of becoming a log dump.
That pattern generalizes.
When the work is a mission, the system should decide the unit of context, the worker role, the tools, the handoff, and the verification path for each piece of the job. A task is not really executable until it has:
- a worker;
- a model or model policy;
- a scoped context package;
- the right tools, skills, and MCPs;
- acceptance criteria;
- a budget;
- a fallback path;
- a verification method.
This is also where model choice becomes more interesting than "which model is best?"
Some steps need the strongest available reasoning model. Some need a code agent with repo context. Some need a cheaper model for extraction or deduping. Some need a local model because the context is private. Some need two independent workers and a reviewer because the cost of a bad decision is high.
A mission should not be locked to one model by default. It should be able to route work based on capability, cost, privacy, latency, stability, and evidence.
The mission has to survive the worker
A mission may begin in one execution environment and continue in another. Some steps should run close to local files, repos, secrets, subscriptions, or private context. Other steps need cloud durability because the laptop closes, retries need to happen, evidence arrives later, or another person needs to review the same state.
That deserves its own architectural discussion, but the implication for the mission model is straightforward: neither the local process nor the cloud job should own the work. The durable state should live at the mission level.
The same is true for models and vendors. A session tied to one provider inherits that provider's lifecycle, pricing, context behavior, memory system, tool surface, and policy choices. That may be fine for a short run. It is fragile for work that spans days, evidence windows, external actions, and accumulated decisions.
The durable learning should live above the worker.
If a human rejects a message because the tone is wrong, that should affect future drafts regardless of which model writes them. If a branch fails because the evidence is weak, the mission should remember the reason without dragging the whole failed transcript forward. If a model becomes unavailable or a vendor changes behavior, the mission should preserve the contract, artifacts, branch history, and next action so another worker can continue.
The session is where some of the work happens. The mission is the state of the work itself.
Receipts make the work accountable
As soon as agents work over hours, across sessions, or across models, logs are not enough.
Logs are useful for debugging. They are not enough to understand whether the work was worth doing.
A mission needs a receipt for the same reason any serious process needs accounting. Work that spends time, tokens, tool calls, and human attention needs an accountable record.
A mission receipt should answer:
- What was the mission?
- What was the contract?
- What subtasks or experiments ran?
- Which workers, models, tools, skills, and MCPs were used?
- Where did the system spend tokens or money?
- What artifacts were produced?
- What evidence came back?
- Which branches failed or were pruned?
- What did the system learn?
- Which human decisions were required?
- What should happen next?
Without that artifact, token spend becomes hard to reason about. A system can burn budget on retries, wander down failed branches, repeatedly reconstruct context, or ask for unnecessary human review without creating an accountable unit of progress.
Receipts are also how mission systems improve. A receipt is not just a summary for the user. It is the structured record that lets the next mission avoid the same mistake, reuse the same decision, route a similar task differently, or know when a cheaper model was good enough.
Learnings are part of the receipt. They do not replace it.
A learning says what the system inferred. A receipt says what happened, what it cost, what evidence supports it, and what should happen next.
What we are building toward
The current wave of agent work is being invented in practice. People are building loops, spawning sessions, wiring tools, assigning subagents, saving memory files, and trying to make larger jobs hold together.
That experimentation is useful because it reveals the missing object. Larger agent work needs a way to define the contract, govern context and tools, route across workers and models, survive failed branches, track evidence, ask for judgment, and account for spend.
We are building Medley around this premise: as the layer above individual agent harnesses emerges, the durable unit above it should be the mission, not the session. The product is not public yet, but this is the direction we are working toward — mission state that can define the contract, govern context and tools, route across workers and models, track evidence, preserve branch history, account for spend, and bring humans in for judgment through an attention queue.
The important shift is operational, not semantic. Sessions were a good container for early agent work. Missions are the container larger AI work now needs. For more on that shift, see Missions vs. Sessions.